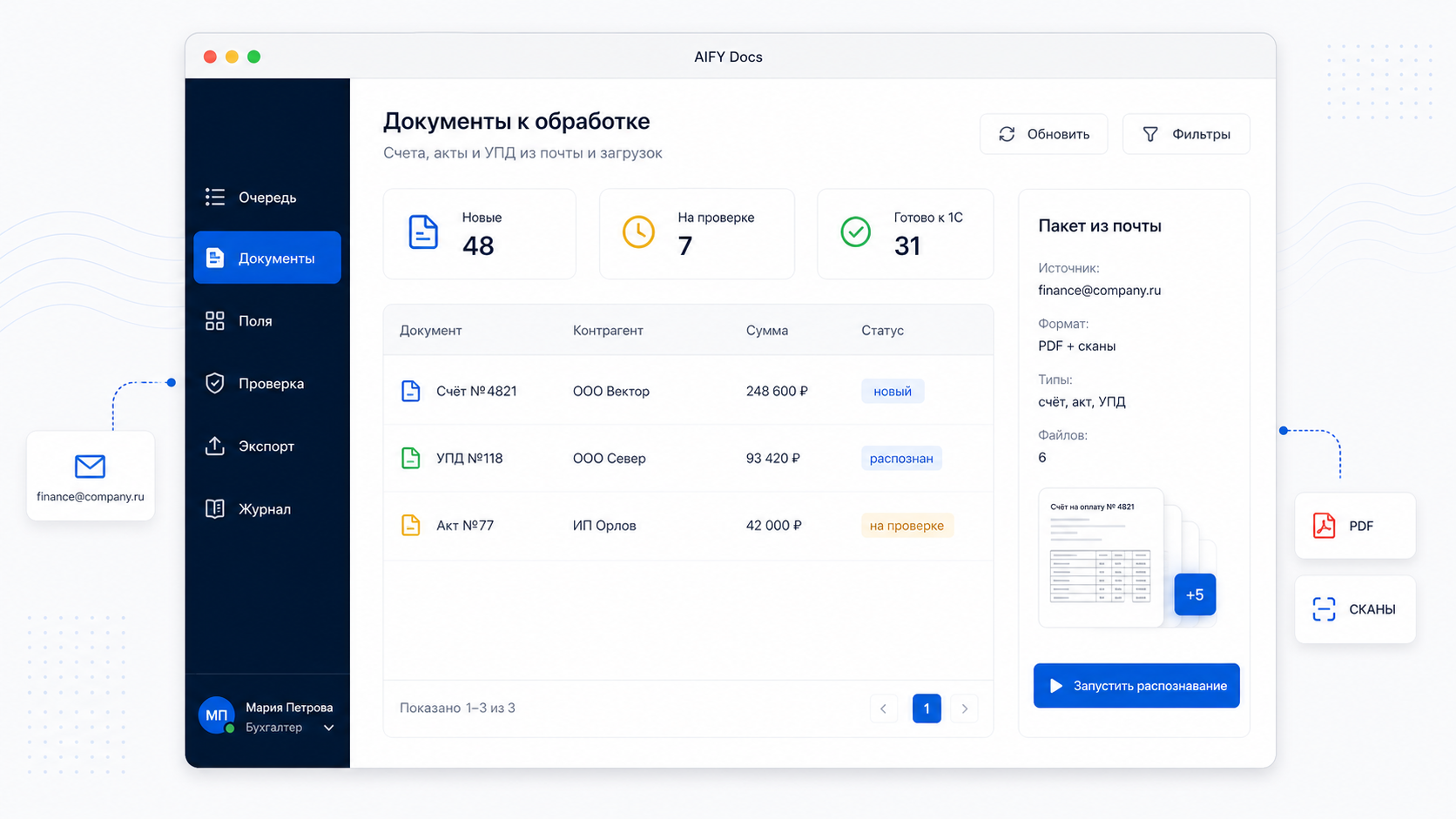
Первый слой — нормализация входа. Документы приходят как PDF, сканы, фотографии или архивы из почты. Система определяет тип файла, качество изображения, количество страниц, поворот, наличие таблиц и отправляет документ в нужную очередь обработки.
Для бизнеса это снимает первую ручную операцию: бухгалтеру не нужно сортировать поток на счета, акты и УПД до того, как документ попал в учётную систему.
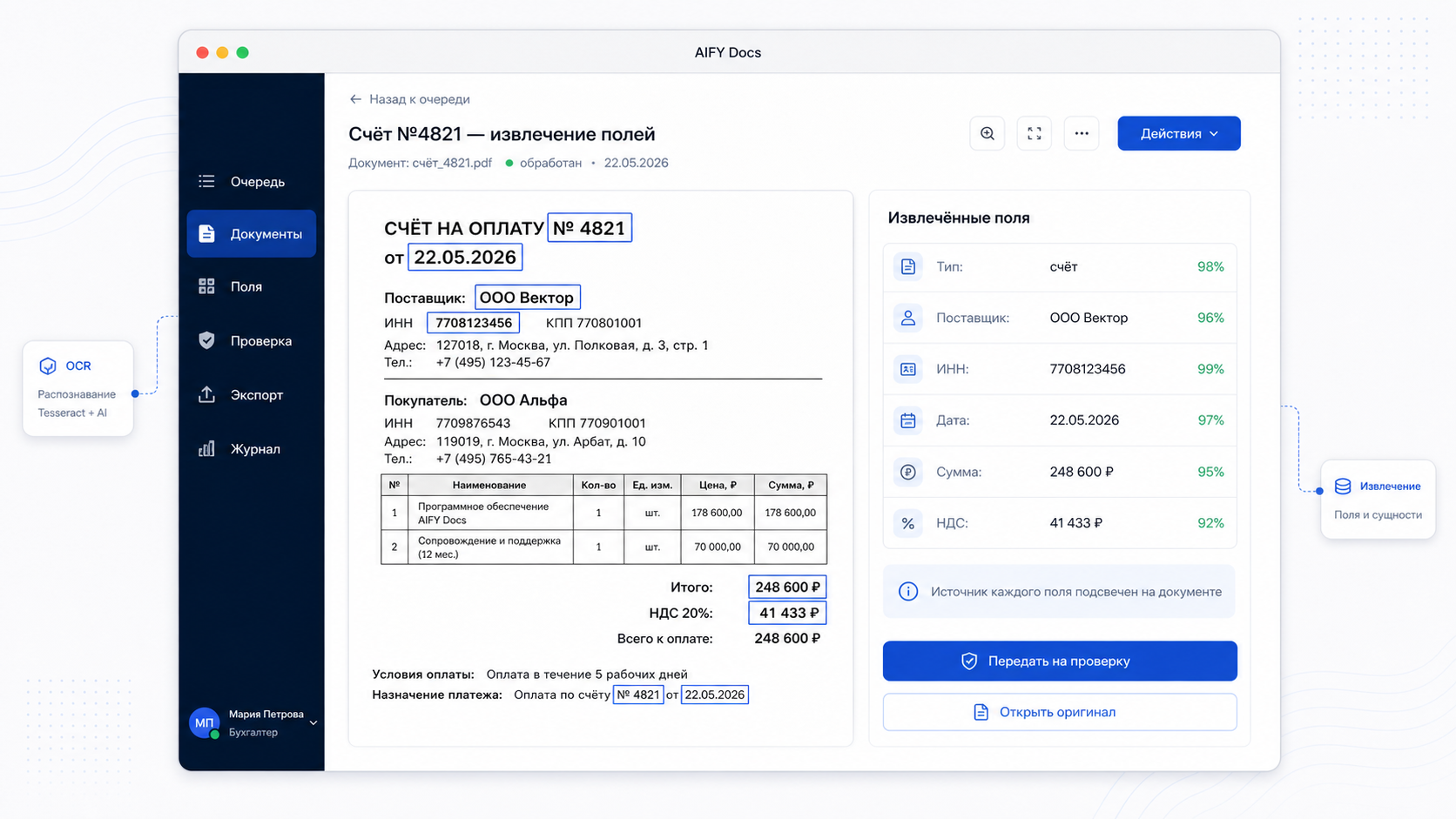
После OCR система получает не просто строку текста, а разметку страницы: блоки, строки, таблицы и координаты. Это принципиально важно для проверки: если модель извлекла сумму или ИНН, оператор должен увидеть место на исходном документе.
Так появляется связка «поле — значение — источник», которая делает результат объяснимым и пригодным для ручного контроля.
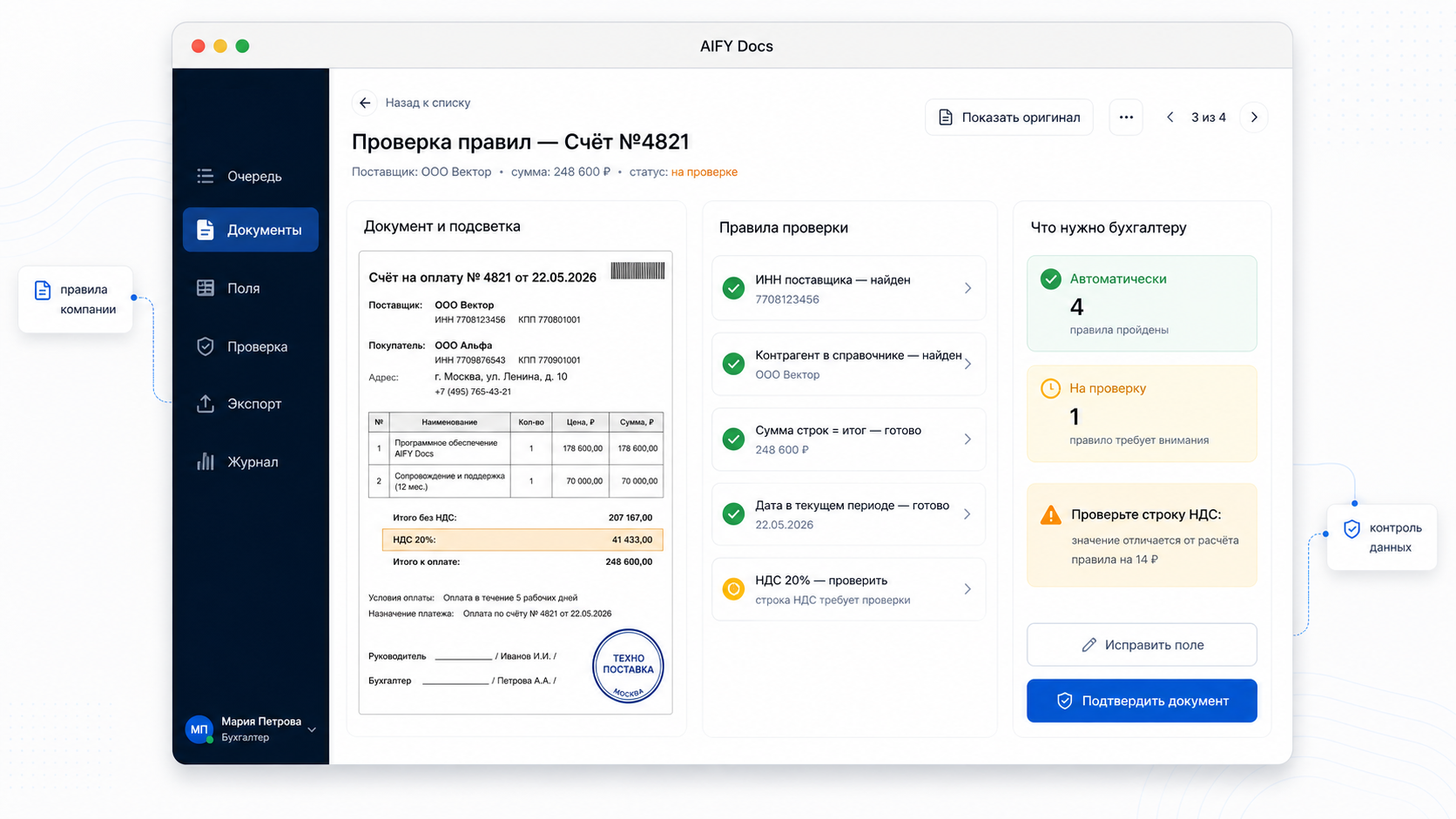
Дальше включаются бизнес-правила. Для первички важно сверить ИНН, контрагента, дату, НДС, сумму строк и итог. Если правило не проходит, система должна показать не общий статус «ошибка», а конкретную причину и поле, которое нужно проверить.
Такой слой снижает риск тихой автоматизации: документ либо проходит набор проверок, либо попадает оператору с понятной причиной.
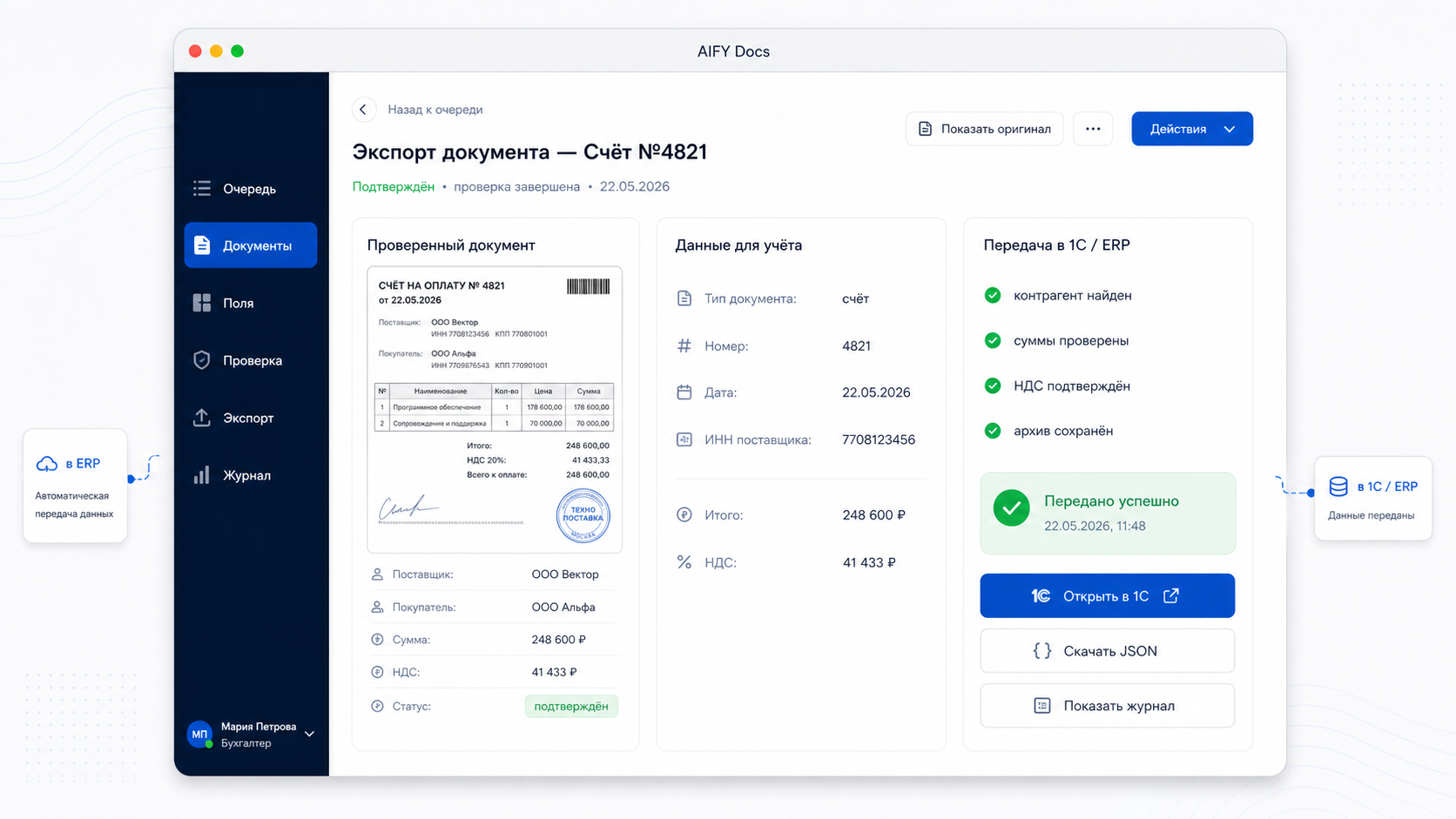
Финальный результат — структурированный объект для учётной системы. Он содержит поля, статус проверки, ошибки, ссылки на исходный документ, журнал действий и формат передачи. Такой объект можно отправить в 1С, ERP, архив или внутренний API без повторного ручного ввода.
Именно здесь OCR превращается в бизнес-процесс: бухгалтерия получает не распознанный текст, а проверяемые данные, готовые к проведению или точечной ручной правке.
Такой кейс полезен компаниям, где первичные документы идут потоком: система забирает ручной перенос, оставляет человеку только спорные места и сохраняет проверяемость каждого проведённого документа.